Why do thinking language models like DeepSeek R1 outperform their base counterparts?
Despite consistent performance gains, it remains unclear to what extent thinking models learn entirely new reasoning capabilities or repurpose pre-existing base model ones.
In this work, we propose a hybrid model where we activate reasoning mechanisms in base models at the right time to elicit thinking-model-level reasoning chains, implying that thinking models exploit already existing capabilities.
To ground our analysis, we introduce an unsupervised, bottom-up approach for uncovering human-interpretable reasoning behaviors in thinking models.
This approach provides an unbiased method to discover reasoning behaviors without imposing manual or LLM-derived assumptions.
Across three base and four thinking models, using GSM8K and MATH500, our hybrid model recovers up to 91% of the performance gap to thinking models without any weight updates while steering only 12% of tokens.
Concretely, our empirical setup provides a simple, causal way to test the effectiveness of existing reasoning mechanisms in base models by invoking them directly and measuring the resulting task performance.
More broadly, these results reframe our understanding of how thinking models are trained: pre-training is when models acquire most of their reasoning mechanisms, and post-training teaches efficient deployment of these mechanisms at the right time, enabling efficient use of their inference-time compute.
Mechanistic Interpretability Workshop at NeurIPS 2025
Interactive Demo
🤖
Select a model pair to begin
Click one of the buttons above to explore how hybrid steering works
Question
Base Model
Hybrid Model
Thinking Model
Introduction
Large Language Models (LLMs) have recently demonstrated remarkable capabilities in reasoning tasks when given additional inference time to think through problems step-by-step. Thinking models, also known as reasoning models, or models using inference-time compute, are a type of language model designed to generate long chains of reasoning before arriving at a final answer.
Examples of models in this category include Anthropic's Claude 3.7 Sonnet, OpenAI's o3, Gemini 2.5 Pro, DeepSeek's R1, and Qwen's QwQ 32B.
All these thinking models significantly outperform their base counterparts on challenging reasoning benchmarks. However, a fundamental question remains: What is the difference between base and thinking models that allows the latter to achieve superior performance?
Prior work has suggested several hypotheses: (1) thinking models acquire entirely new reasoning capabilities through specialized training; (2) reinforcement learning (RL) teaches them to structure their reasoning more effectively; (3) RL teaches them to repurpose pre-existing base model representations for new mechanisms; or (4) the additional inference time simply allows more computation to be applied to difficult problems. In this paper, we present evidence for a more nuanced explanation: not only do base models already possess the fundamental reasoning capabilities, but thinking models learn when to deploy these capabilities in a structured sequence.
Key Contributions
To support our analysis, we develop an unsupervised clustering methodology to derive an interpretable taxonomy of reasoning mechanisms that thinking models employ during their chains of thought, forming the building blocks of complex problem-solving. We demonstrate that base models can perform each reasoning behavior when appropriate steering vectors are added to their activations. By identifying and applying the right vector at the right step, we can guide pretrained base models to reproduce complete reasoning chains of thinking models.
Unsupervised Taxonomy of Reasoning Mechanisms
Recent work on thinking models has primarily relied on manual inspection of reasoning traces to identify underlying mechanisms. While insightful, such approaches are inherently subjective and may overlook subtle patterns. We develop an unsupervised, bottom-up methodology to discover human-interpretable reasoning mechanisms in thinking models. Our goal is to construct a taxonomy that is: (1) interpretable, with each mechanism having a clear description of its cognitive function; (2) complete, covering the full range of reasoning steps the model uses; and (3) independent, with categories corresponding to distinct cognitive functions with minimal overlap.
We use Top-K Sparse Autoencoders (SAEs) to cluster sentence-level activations from reasoning traces. We train our SAEs on sentence-level activations from 12,102 MMLU-Pro prompts (430,122 sentences total). The SAE configuration directly matches our hypotheses: the dictionary size represents the number of distinct reasoning mechanisms we hypothesize exist, while the parameter K constrains how many mechanisms can be simultaneously active in a single sentence. We deliberately restrict the latent dimension to [5, 50], far smaller than the residual stream size, forcing the SAE to identify the most fundamental dimensions of reasoning variation.
For each discovered cluster, we use an LLM to analyze top exemplar sentences and generate interpretable category titles and descriptions. We evaluate the proposed taxonomies using three metrics: consistency (how well sentences can be classified into categories), completeness (confidence in classification), and independence (semantic distinctness between categories). Our grid search across five models reveals that reasoning mechanisms are well-represented using 10-20 categories.
Hybrid Model Architecture
To investigate whether base models already possess reasoning mechanisms, we propose a hybrid approach that combines base models with steering vectors—directions in activation space that, when added to intermediate activations, induce target behaviors. We leverage the reasoning taxonomies from our SAE analysis to identify steering vectors corresponding to each reasoning mechanism. Since SAEs identify variance-explaining rather than causally important directions, we use steering vector optimization to find the causal directions.
For each reasoning category, we: (1) identify sentences with top activation scores for that category, (2) extract prefix-completion pairs, and (3) optimize a steering vector that, when applied to the base model, maximizes prediction loss for the thinking model's completion while minimizing likelihood of the base model's completion. We select layers at ~37% of model depth (shown to be most causal in prior work) and train steering vectors at all token positions. Additionally, we train a general bias vector on randomly sampled thinking rollouts to capture general patterns like using first person, which we apply frozen alongside category-specific vectors.
During generation, our hybrid model computes SAE activations at each token position to identify the most active reasoning category, then applies the corresponding steering vector. To adjust steering strength, we test multiple coefficients and steering windows (number of tokens before current position to apply steering), selecting the steered token with lowest perplexity according to the thinking model. This ensures the thinking model stays in-distribution.
Importantly, this approach requires no parameter updates to the base model. The effectiveness with only 15 distinct steering vectors rules out the explanation that steering simply biases toward specific output tokens—there is insufficient information to generate appropriate outputs across hundreds of diverse problems through token-level manipulation alone. Instead, our results suggest steering activates latent reasoning modes within the base model.
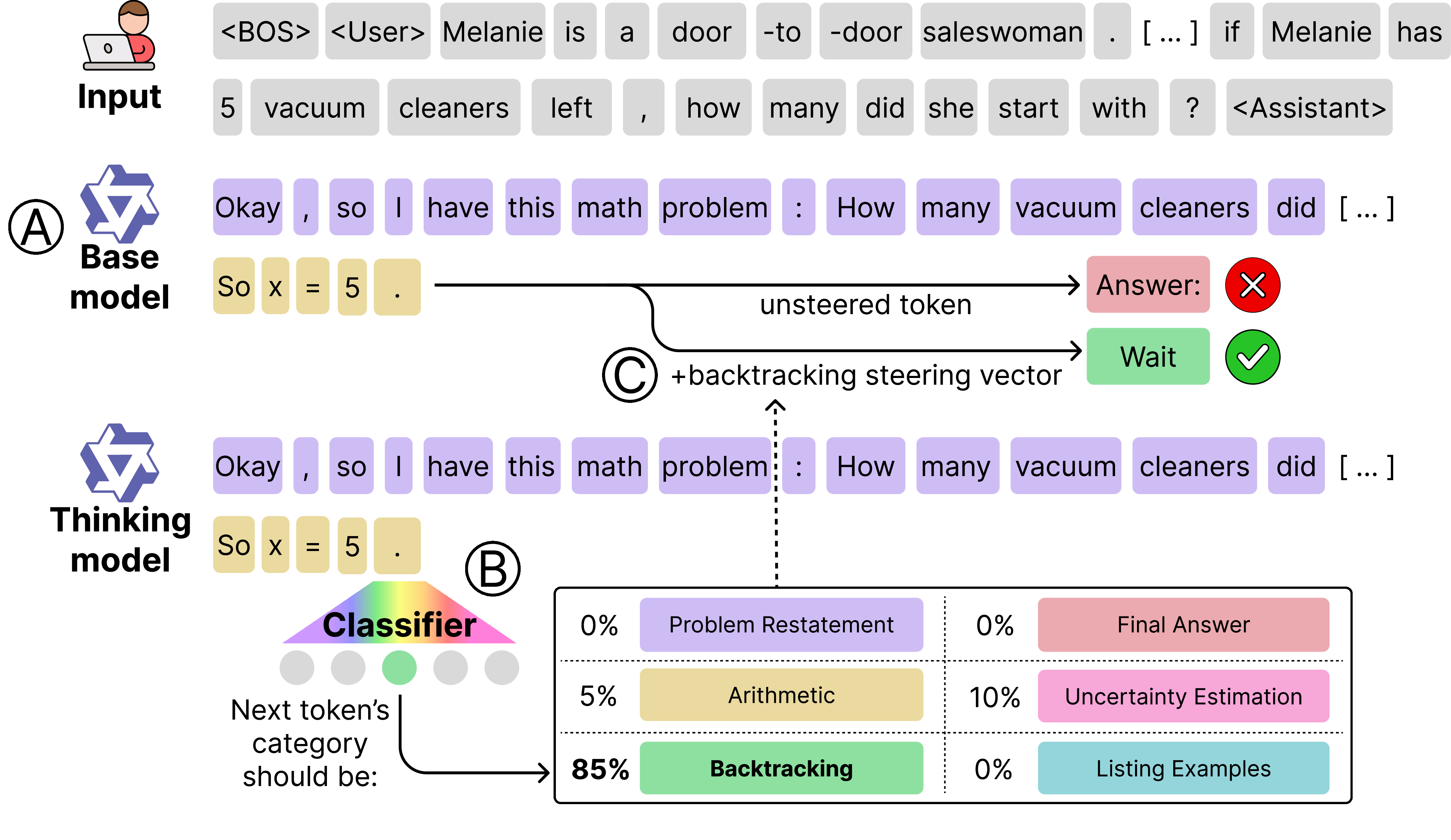
Hybrid Models Unlock Reasoning Model-Level Behavior with Minimal Intervention.
Overview of our approach for steering base language models to reason like thinking models.
(A) We use the base model as the primary generator of tokens in the output sequence.
(B) For each token position, we evaluate the current rollout in a target thinking model and use a "thinking model activation classifier" to detect the reasoning mechanism that should be applied next.
(C) When the classifier detects a reasoning step, we apply a corresponding steering vector to the base model's activations, triggering structured reasoning behavior.
This approach shows that base models already possess latent reasoning abilities, and that these can be reliably activated without any parameter updates, bridging much of the gap to full reasoning models with minimal extra machinery.
Results
The evaluation for our steered base model approach focuses on thinking models across diverse architectures and parameter scales, including models trained with distillation (DeepSeek-R1-Distill series) and models trained directly with RLVR (QwQ-32B). The results show that this approach substantially lifts base model performance, recovering up to 91% of the performance gap between base and thinking models on GSM8K and MATH500 benchmarks without any weight updates, and steering only up to 21% of tokens.
This finding provides strong evidence that reinforcement learning with verifiable rewards (RLVR) used to train thinking models primarily teaches when to activate pre-existing skills rather than teaching how to execute those skills. This perspective has direct implications for more efficient training of reasoning in future language models.
Ablation Studies
To assess the hybrid model's components, we ablate three factors: the specificity of the learned steering vectors, the timing of their application, and the contribution of the bias vector. We run these ablations on Qwen2.5-32B as the base with QwQ-32B (RLVR) as the thinking model on MATH500, the setting with the strongest hybrid performance (91% gap recovery). We compare three ablations against the full hybrid model:
Only-bias: Uses only the general bias vector for steering, without any category-specific steering vectors
Random-vectors: Uses random unit vectors instead of the trained steering vectors (plus bias vector)
Random-firing: Randomly selects which reasoning category to activate at each token (plus bias vector), bypassing the SAE oracle
The results show that Only-bias achieves 76.8%, indicating the bias helps but category-specific steering vectors are necessary; Random-vectors achieves 77.2%, confirming that the learned directions are specific rather than generic; Random-firing reaches 77.8%, showing that proper timing of activation is crucial. Together, these findings support that effectiveness comes from specific learned directions applied with correct, category-timed activation, consistent with our claim that thinking models primarily learn when to deploy reasoning mechanisms.
More Resources
Explore additional materials to understand our methodology and results in greater depth:
QwQ-32B Reasoning Categories
View the complete taxonomy of 10 reasoning categories discovered in QwQ-32B through unsupervised clustering, with representative examples for each category.
Explore a complete thinking trace from QwQ-32B on a physics problem, with each sentence color-coded by its reasoning category to visualize cognitive transitions.
If you find our work useful, please consider citing:
@misc{venhoff2025basemodelsknowreason,
title={Base Models Know How to Reason, Thinking Models Learn When},
author={Constantin Venhoff and Iván Arcuschin and Philip Torr and Arthur Conmy and Neel Nanda},
year={2025},
eprint={2510.07364},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2510.07364},
}